Poniżej przedstawione są pojęcia związane z importem specjalnym, danymi wejściowymi oraz mechanizmami przekształcania danych.
Pole (danych)
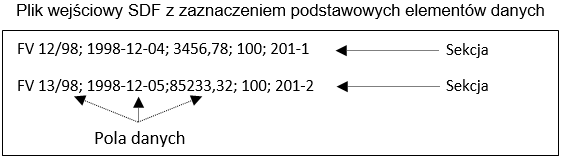
Jest to elementarna, informacja w pliku danych, opisująca jedną wartość (np. kwota, konto, data, numer, opis itp.). Poniżej pokazano przykładowe trzy pola danych oddzielone od siebie separatorem (średnikiem):
2457;Abacki;Janusz
Nazwa (pola)
Opcjonalna jawnie podana nazwa pola przechowującego określoną wartość. W zależności od formatu w pliku danych mogą być umieszczone tylko pola danych (bez nazwy), lub też każde pole danych może mieć dodatkowo swoją nazwę.
Poniżej pokazano przykładowe dane z jawnie podaną nazwą pola oraz znakiem równości oddzielającym nazwę i wartość:
numer=2457
nazwisko=Abacki
imię=Janusz
Sekcja wejściowa
Jest to elementarna porcja danych (grupa), zawierająca komplet informacji (pól) niezbędnych do jej przetworzenia i wczytania do programu importującego dane. Składa się z pól oraz z podsekcji. Przykładem sekcji jest informacja o całym jednym dokumencie lub kontrahencie. Dla formatów SDF, CDF, COMMA jest to jeden wiersz z pliku wejściowego, dla pozostałych formatów jest to grupa kolejnych linii tworzących komplet danych. Poniżej podano przykładowe trzy sekcje (w tym przypadku jedna sekcja to jedna linia) z pliku w formacie SDF, zawierające dane pracowników:
2457;Abacki;Janusz
2458;Kowalski;Maciej
2459;Zawadzki;Zenon
Podsekcja
Jest to logicznie wydzielona grupa informacji w ramach sekcji. Składa się z pól oraz ew. z dalszych podsekcji. Przykładem podsekcji może być informacja o kwotach w rejestrze VAT lub informacje o jednym zapisie na koncie. Podział sekcji danych na podsekcje jest często umowny. Poniżej pokazano podsekcję zapisu w sekcji dokumentu, w formacie AMS
Dokument{
data=12-02-2000
Zapis{
kwota=234,56
konto=201-1
}
}
Plik wejściowy
Jest to plik na dysku, zawierający dane importowane. każdy plik danych zawiera szereg powtarzających się informacji (sekcji), opisujących np. kolejne importowane dokumenty. Każdy plik danych jest czytany sekwencyjnie, sekcja po sekcji od początku do końca. W pewnych przypadkach wszystkie informacje wczytywane w jednej operacji importu mogą być zawarte w kilku plikach danych.
Szablon
Jest to program napisany w specjalnym języku programowania, dzięki któremu dokonywana jest interpretacja danych wejściowych i zamiana do postaci wymaganej przez program odbierający dane. Dzięki szablonowi dane wejściowe które mogą być zapisane na wiele różnych sposobów, zamieniane są do postaci akceptowalnej przez program odbierający dane. W najprostszym wariancie szablon zawiera przypisania (przyporządkowania) kolejnych pól wejściowych do odpowiednich pól w programie. W bardziej złożonych przypadkach w szablonie znajdują się dodatkowo wyrażenia logiczne, arytmetyczne lub inne złożone operacje na danych.
Szablon XSLT
Jest to program napisany w języku XSLT, dzięki któremu dokonywana jest transformacja danych wejściowych w formacie XML i zamiana danych do postaci AMS, które następnie przy pomocy Szablonu są odbierane przez program. Dzięki szablonowi XSLT dane wejściowe mogą być zapisane w dowolnym formacie XML. W szablonie XSLT używany jest ustandaryzowany język XPath do dokonywania prostych transformacji i mapowań.
Sekcja wyjściowa
Zakresem danych i konstrukcją logiczną odpowiada informacjom w bazie danych programu Finanse i Księgowość. Jest to elementarna porcja danych, utworzona przez wczytanie i przetworzenie jednej sekcji wejściowej danych. Postać sekcji wyjściowej jest ściśle ustalona, zgodna z wbudowanymi procedurami kontroli poprawności oraz zapisywania danych do baz danych programu. Sekcje wyjściowe tworzy się jawnie poprzez wykonanie odpowiednich poleceń w szablonie. Pola danych w sekcji wyjściowej tworzy się przez wykonanie odpowiednich poleceń podstawienia danych.
Postać sekcji wyjściowej jest zależna od rodzaju wczytywanych danych. Inna jest dla kartotek, inna dla poszczególnych typów dokumentów.
Sekcje wyjściowe są tworzone przez szablon. Można w ten sposób utworzyć absolutnie dowolną strukturę sekcji i podsekcji wyjściowych oraz ich pól danych. Aby jednak dane wyjściowe nie zostały przez program odrzucone na etapie kontroli poprawności, szablon musi być tak zaprojektowany, aby stworzyć właściwą strukturę tych danych, zgodną ze specyfikacją programu Finanse i Księgowość. W przyszłości mechanizm importu specjalnego może być zastosowany w innych programach Systemu Symfonia, wówczas wszystkie opisane tu elementy i mechanizmy pozostaną niezmienione, inna będzie tylko postać danych wyjściowych, wymaganych i akceptowanych przez program odbierający dane.
Uzgodnienia
Proces łączenia informacji z pliku danych z informacjami zawartymi w programie Finanse i księgowość. Przykładowo każdy oddzielny typ dokumentu importowanego należy połączyć z właściwym, odpowiadającym mu typem dokumentu w programie. Każde raz dokonane uzgodnienie jest pamiętane przez program i wykorzystywane podczas importowania kolejnych danych.
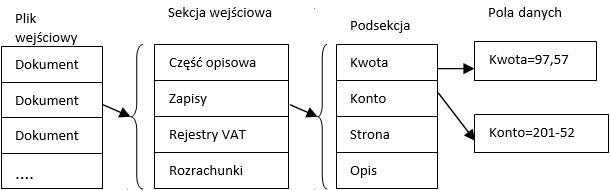
Elementy danych importowanych