Więcej informacji - Jak dodać system bankowy?
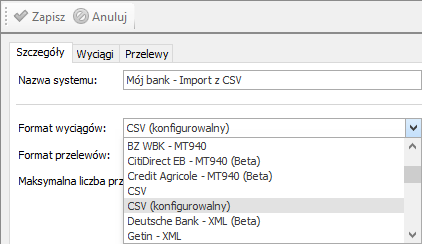
Format wyciągów bankowych CSV (konfigurowany) przeznaczony jest do obsługi importu operacji bankowych z plików CSV. Format ten obsługuje import z CSV podobnie do formatu wyciągów CSV, ale zawiera wsparcie kreatora konfiguracji.
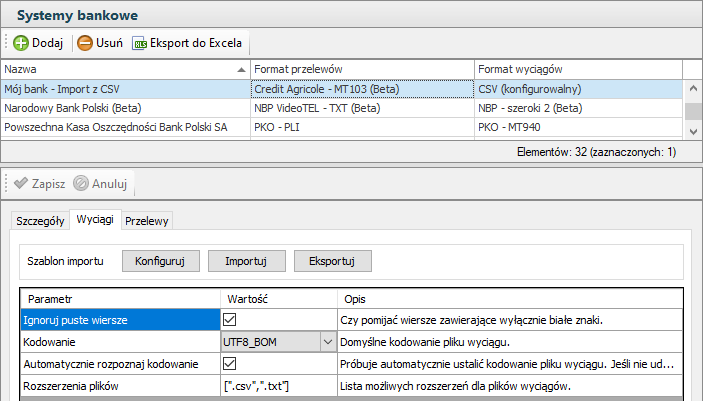
Dla tego formatu wyciągów na zakładce Wyciągi dostępne są dodatkowe opcje:
•Konfiguruj – otwiera opisany dalej kreator konfiguracji importu z pliku CSV.
•Importuj – importuje konfigurację z pliku .Json.
•Eksportuj – eksportuje bieżącą konfigurację do pliku .Json.
Podstawowe parametry:
Ignoruj puste wiersze – gdy zaznaczone, import pominie puste wiersze w pliku CSV.
Kodowanie – domyślna strona kodowa pliku wyciągu. Sprawdź to ustawienie jeśli np. występują problemy z importem polskich znaków.
Automatycznie rozpoznawaj kodowanie – gdy zaznaczone, program spróbuje samodzielnie ustalić kodowanie importowanego pliku. Jeśli to się nie uda to zastosowane zostanie kodowanie domyślne.
Rozszerzenia plików – rozpoznawane rozszerzenia plików dla wyciągów bankowych.
Kreator konfiguracji importu z CSV
Kliknięcie przycisku Konfiguruj otwiera okno kreatora konfiguracji.
Kreator konfiguracji nie wykonuje importu danych, ale definiuje szablon dla operacji importu wyciągów bankowych w formacie CSV (konfigurowalny) dla danego systemu bankowego.
Krok 1 Przykładowy plik CSV
W pierwszym kroku kreatora:
1.Kliknij ![]() i wskaż przykładowy plik CSV dla którego przygotowywany będzie szablon importu.
i wskaż przykładowy plik CSV dla którego przygotowywany będzie szablon importu.
2.Wczytany zostanie podgląd pliku CSV, na którym zaznacz tylko importowane wiersze danych z wierszem zawierającym tytuły kolumn. Istotne tu jest aby nie zaznaczać wierszy nagłówka czy stopki pliku z CSV, niezawierających tabelarycznych danych wyciągu.
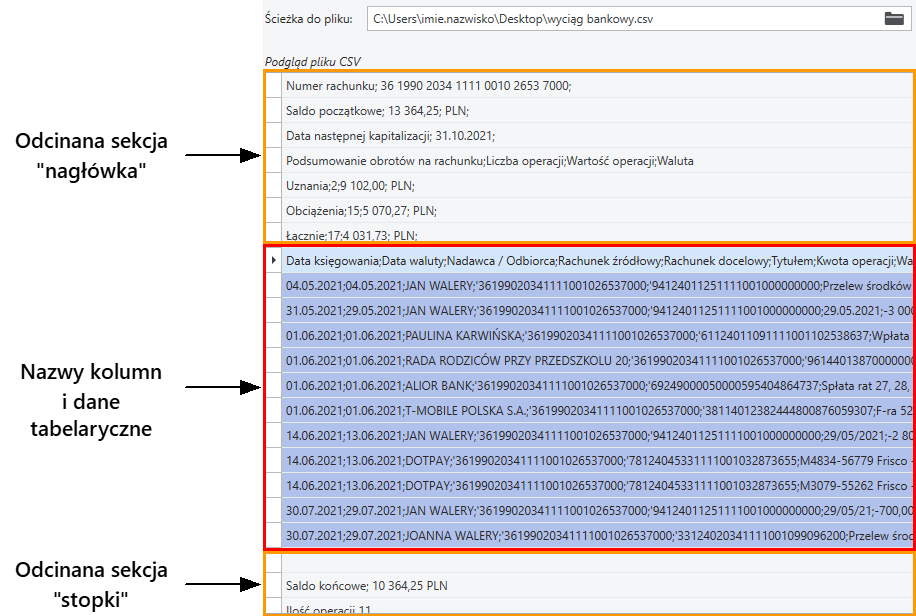
Aby dane z nagłówka i stopki zostały pominięte przy wczytywaniu wyciągu program musi umieć oddzielić je od właściwych danych tabelarycznych.
Zaznaczenie wierszy zawierających dane wyciągu pomaga kreatorowi w określeniu reguł umożliwiających automatyzację tego procesu. Należy jednak pamiętać, że pełna automatyzacja separacji nagłówka i stopki może nie być możliwa we wszystkich przypadkach.
3.Kliknij Dalej aby kontynuować.
Krok 2 Wstępna konfiguracja pliku CSV
Kreator spróbuje rozpoznać definicję formatowania pliku CSV i wstępnie ustawić jej konfigurację. Zweryfikuj i w razie potrzeby popraw ustawienia. Zwróć szczególnie uwagę czy dane podzielone zostały na osobne kolumny (czy poprawnie wykryty został separator pól) oraz czy ustawiony jest prawidłowy kwalifikator tekstu. Kliknij Dalej aby przejść do kolejnego kroku.
Podstawowe ustawienia obejmują:
Separator pól – znak używany do oddzielenia pól(kolumn) danych w pliku CSV ( \t to oznaczenie tabulatora, stosując tą konwencję można jako separatora użyć innych znaków specjalnych).
Kwalifikator tekstu – znak (zazwyczaj cudzysłów " ) oznaczający początek i koniec ciągu importowanych znaków, zwykle dla danych typu tekst.
Tytuły kolumn – oznaczenie, czy plik zawiera wiersz z tytułami kolumn. Jeśli zaznaczone to pierwszy wiersz z danych tabelarycznych traktowany będzie jako zawierający nazwy kolumn i będzie pomijany.
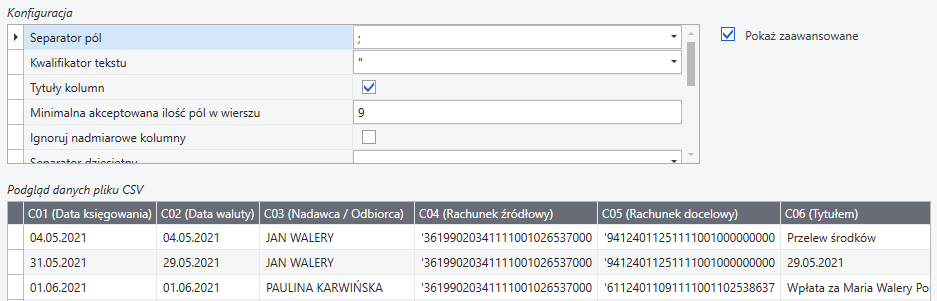
Po zaznaczeniu pola Pokaż zaawansowane wyświetlane są dodatkowe parametry konfiguracji:
Minimalna akceptowalna ilość pól w wierszu – określa minimalną liczbę kolumn danych wymaganą aby zaimportować wiersz. Domyślnie wartość ustalana jest na podstawie wskazanego pliku CSV, jeśli jednak wiemy, że plik nie jest reprezentatywny lub z dokumentacji banku do formatu wyciągu wiemy ile minimalnie może być pól to możemy to poprawić. Wartość ta pomaga w wykryciu wierszy nagłówka/stopki do odcięcia.
Ignoruj nadmiarowe kolumny – ostatnie kolumny nie uwzględnione w schemacie będą ignorowane.
Separator dziesiętny – znak używany jako separator części ułamkowej liczb.
Nagłówek - maksymalna liczba wierszy – określa maksymalną liczbę wierszy w nagłówku, które mogą być automatycznie pominięte, jeśli nie spełniają kryterium minimalnej liczby kolumn. Wykrycie pierwszego wiersza danych oparte jest na warunku z parametru Regex detekcji pierwszego wiersza danych albo Minimalna akceptowalna ilość pól w wierszu.
Nagłówek - minimalna liczba wierszy – określa liczbę wierszy w nagłówku, które zawsze zostaną pominięte. Kreator domyślnie ustawia wartość 0. Ustawiając wartość tego parametru upewnij się, że w pomijanych wierszach nie znajdą się dane, które powinny zostać zaimportowane.
Przy weryfikacji ustawień liczby wierszy nagłówka i stopki wyciągu należy mieć na uwadze, że kreator wykrywa ustawienia na podstawie jednego przykładowego pliku. Jeśli generowany przez bank wyciąg może mieć różną ilość wierszy nagłówka/stopki należy samodzielnie dostosować ustawienia liczby wierszy. Mimo to mogą wystąpić sytuacje, w których prawidłowa obsługa odcinania nagłówka/stopki nie jest możliwa, wtedy pozostaje manualne przygotowanie pliku wyciągu do importu np. przez edycję w Notatniku.
Stopka - maksymalna liczba wierszy – określa maksymalną liczbę wierszy w stopce, które mogą być automatycznie pominięte, jeśli nie spełniają kryterium minimalnej liczby kolumn (z parametru Minimalna akceptowalna ilość pól w wierszu).
Stopka - minimalna liczba wierszy – określa liczbę wierszy w stopce, które zawsze zostaną pominięte. Kreator domyślnie ustawia wartość 0. Ustawiając wartość tego parametru upewnij się, że w pomijanych wierszach nie znajdą się dane, które powinny zostać zaimportowane.
Kreator nie ustawia automatycznie parametrów minimalnej liczby odcinanych wierszy stopki. Ustawiając odcinanie ostatnich wierszy stopki z pliku CSV, należy mieć na uwadze to, że wykrywanie końca tabeli z danymi wykonywane jest na podstawie liczby kolumn (tzn. czy spełniony jest warunek z parametru Minimalna akceptowalna liczba pól w wierszu).
Jeśli liczba wierszy stopki jest zmienna, oraz w stopce występuje tyle samo kolumn (separatorów pól) co w wierszu danych to mogą wystąpić problemy z wykrywaniem końca importowanych danych. W skutek tego może zostać zaimportowanych za dużo lub za mało ostatnich wierszy danych.
Pierwsze i ostatnie puste wiersze w pliku są usuwane przed zastosowaniem reguł dla odcinania nagłówka i stopki.
Regex detekcji pierwszego wiersza danych – wyrażenie regularne pomagające wykryć pierwszy wiersz danych tabelarycznych.
Ignoruj puste wiersze – gdy zaznaczone: pominięte zostaną wiersze zawierające wyłącznie białe znaki (spacja, tabulacja, koniec wiersza).
Automatycznie rozpoznawaj kodowanie – gdy zaznaczone: program spróbuje samodzielnie rozpoznać użytą w pliku stronę kodową. Jeśli to się nie uda to zastosowane zostanie kodowanie domyślne.
Krok 3 Mapowanie danych
W kolejnym kroku należy dokonać mapowania kolumn w pliku CSV z polami dokumentu operacji bankowej w RDF.
Sparuj odpowiednie kolumny z pliku CSV (tabela Kolumny do zmapowania) z polami danych w repozytorium dokumentów (tabela Pola obiektu biznesowego). Jeśli potrzebne jest przy mapowaniu zastosowanie dodatkowej logiki, np. podzielenia lub połączenia pól sprawdź opis dla mapowania zaawansowanego.
|
Wymagane do zmapowania są pola: Data operacji, Kwota, Numer rachunku (którego dotyczy wyciąg).
Aby zobaczyć więcej informacji o polu obiektu biznesowego najedź na nie kursorem myszy.

Mapowanie - przeciągnij i upuść
Najprostszym sposobem na zmapowanie kolumn jest przeciągnięcie danych z tabeli kolumny do zmapowania do wiersza wybranego pola obiektu biznesowego.
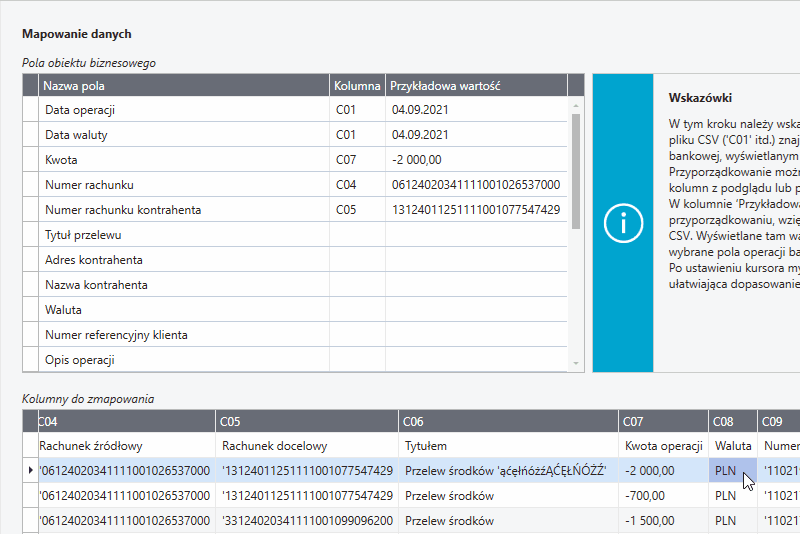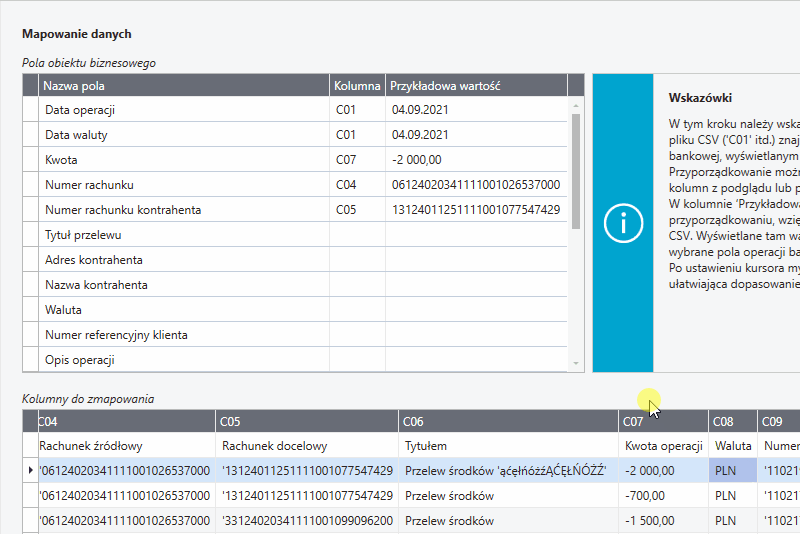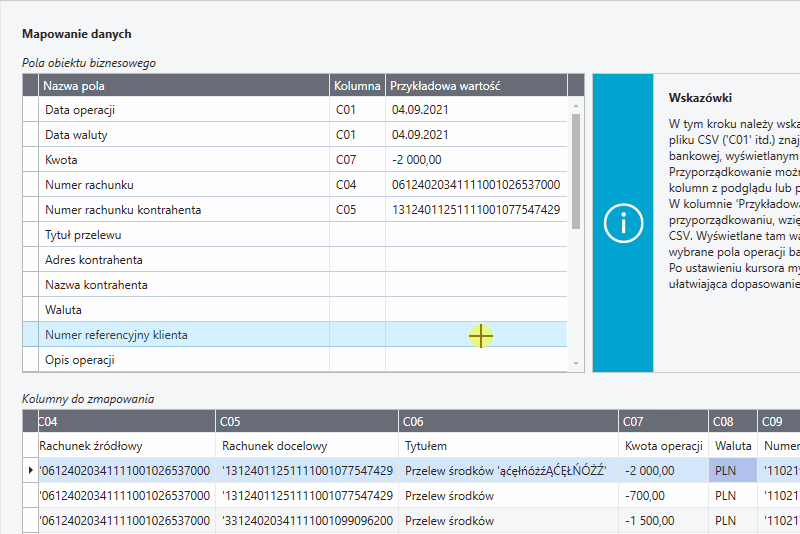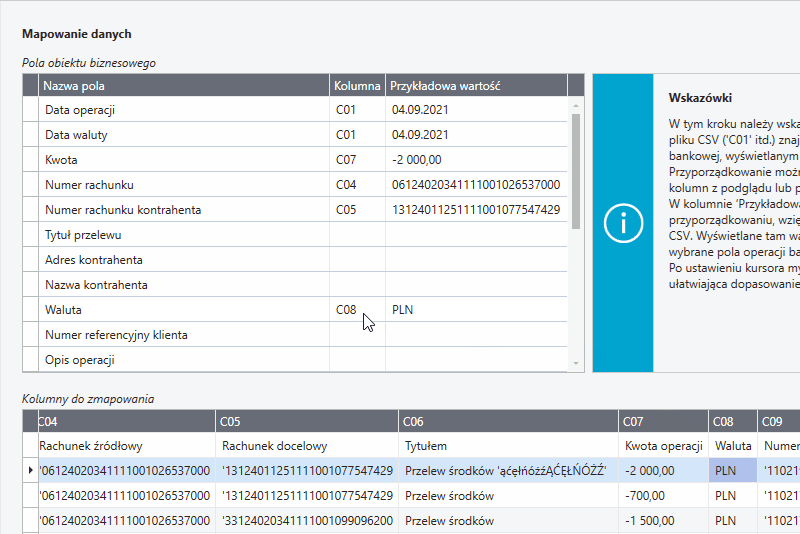
W tabeli Pola obiektu biznesowego w polach Kolumna widoczne są identyfikatory (C01, C02 itp.) zmapowanych kolumn z pliku CSV. W znajdującej się obok kolumnie Przykładowa wartość prezentowane są zmapowane wartości z aktualnie wybranego wiersza tabeli Kolumny do zmapowania.
Mapowanie - zaawansowane
Definicja powiązania kolumny z polami dokumentu operacji bankowej w RDF może być złożona:
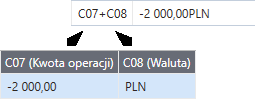
•z kilku kolumn / wartości tekstowych / fragmentów kolumn z pliku CSV za pomocą operatora + np.:
C07 + C08
Zawartość kolumny złożona zostanie z wartości kolumn C07 oraz C08 (z pliku CSV).
•z wartości tekstowej umieszczonej w cudzysłowach np.:
"Tytuł:" + C08
W kolumnie Tytuł przelewu umieszczony zostanie tekst Tytuł: i po nim dołączona zostanie wartość kolumny C08 (z pliku CSV).
Na przykład "Tytuł: "+C06+" ("+C03+")":

Po tekście Tytuł: dodawana jest wartość z kolumny C06 a następnie w nawiasach dodawana jest wartość z kolumny C03.
Po zmapowaniu kolumn kliknij przycisk Zakończ aby zapisać ustawienia szablonu importu.
Obsługa nietypowych sytuacji
Brak kolumny z rachunkiem bankowym firmy
Jeśli dane wyciągu bankowego nie zawierają kolumny z rachunkiem bankowym, którego dotyczy wyciąg, to w definicji zamiast mapowania można wprowadzić rachunek bankowy dla którego stosowany będzie dany szablon, np.:
